


自動車の完全自動運転現実化については喧々諤々の議論が続いていますが、それに向けて技術は確実に進歩しています。その要となるコンピューターチップについて、テスラがAutonomy Day(投資家向けの会合)でのプレゼンテーションで詳しく解説をしていました。かなり専門的なプレゼンだったのですが、CleanTechnica上でさらに専門的な見地からの驚きを解説した記事が投稿されました。全編、日本語訳にしてお届けします。
元記事:Tesla’s New HW3 Self-Driving ComputerーIt’s A Beast (CleanTechnica Deep Dive) by Chanan Bos on『CleanTechnica』
【関連記事】
『100万台のロボタクシーが町を走る近未来〜『TESLA AUTONOMY INVESTOR DAY』で語られた内容を徹底チェック!』
はじめに
1カ月前、テスラは完全自動運転用の新しいチップに関するいくつかの秘密を明かしました。しかし、このプレゼンテーションを作った数人は、聴衆全員がマイクロプロセッサのデザインとエンジニア技術に関して多くの知識を持っているわけではない、という前提を考慮し忘れたようです。
私もこの分野にそこまで精通しているわけではありませんが、結構長い間コンピューターオタクをやっておりまして、プレゼンの中の重要な部分を自分なりにピックアップをし、何故これがエキサイティングな話なのか、そしてテスラがどのように頭一つ抜けているのかは分かっています。さらにこのチップがどうなっていくのかについての予測も書いていきたいと思います。
警告:上記のように書きましたが、それでもこのプレゼンテーションはかなりテクニカルです。鍵となる部分についてはできるだけ平易な文章で書くように努めます。
基盤上には何があるのか?
まずはじめに、チップの全体図が見えます。チップは‘完全冗長化’されており、これが意味するところはチップのどのシステムにエラーが生じても、コンピューターが何もなかったかのように動作し続けられる、という事です。チップの右側にはすべてのカメラのコネクター、左側には電源が接続される場所と、入力・出力用のコネクターがあります。真ん中には、ここでの主役、2つのプロセッサ(ここで言う‘プロセッサ’とは本来の意味と少し違います。後ほどご説明します)が位置します。テスラは2つのプロセッサを、パフォーマンス向上のためではなく、冗長性と結果の相互参照用に使っています。

画像はすべてCleanTechnicaの元記事より
プロセッサの左下方向(水色の部分)にはオペレーティング・システムの入ったフラッシュメモリーがあります。現時点でチップの容量は分かっていませんが、一般的に500GBのマイクロSDカードを買える事を考えると、かなり大きいものになる事が予想されます。
各プロセッサの左右には、4つのLPDDR4 RAMチップがあります(緑の部分)。プロセッサがサムスン製なので、RAMもそうなのかと思われがちですが、実は違います。

チップをよく見てみると、小さなロゴが見えます。サムスンはこのようなロゴをRAMチップには載せません。しかしマイクロンは載せますし、特にチップに通常載せられるものはこの画像のものによく似ています。マイクロンはLPDDR4 RAMを製造しており、さらに自動車産業をターゲットにした商品ラインもあります。テスラがサムスンではなくマイクロンを選んだ理由は、恐らく彼らのLPDDR4 RAMのクロックレートが高いからで、マイクロンが2133MHzであるのに対し、サムスンの方は1600MHzとなっています。
LPDDR4 チップはDRAMの一種で、記事の後半DRAMとして出てきます。ある観点から言うと、LPDDR4はDDR4の低性能バージョンとなります。DDR4は現在デスクトップパソコンやノートパソコンに使われています。LPDDR4はDDR4よりも少し遅いのですが、種類によってはDDR3よりも良いパフォーマンスを出す事があります。LPDDR4は現在スマートフォン用に使われています。

ヒートスプレッダを取り除くとダイが見え、テスラはこれについて多くの情報を話してくれました。ダイのサイズは約260㎟です。もう少し具体的に話しますと、例えばiPhoneのプロセッサは約80~120㎟で、インテルのノート/デスクトップパソコンのダイは最大約180㎟、NVIDIAのXavierチップのダイは350㎟、そしてグラフィックカード上のチップは400から800㎟になります。
テスラのSoCの肝(もしくは脳)
まず大きな誤解を解いておきましょう。この記事の始めの方でテスラのチップをプロセッサと呼びましたが、これは正確ではありません。実際にはすべてのシステムが入ったSoC(System-on-a-chip=集積回路製品)なのです。テスラはプロセッサ、グラフィックカード、ニューラルプロセッサ、そしてその他多くの、ほとんどの人がその存在すら知らなかった様なものをこの一つのチップに搭載したのです。
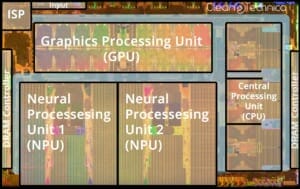
テスラはカメラが撮ったデータを引き合いに、全体のプロセスを説明しています。まず、データは‘インプット’として最大25億ピクセル/秒のレートで入っていきますが、これは21台のカメラが同時に送信するフルHD1080p 60fps(fps = 毎秒のフレーム数)と同じ位の処理速度です。これは現在車に搭載されているセンサーが作り出すよりも相当大きなデータ量です。その後このデータは先程書いたDRAMに移動しますが、ここは一番スピードの遅い部品であるため、チップの最初の、そして最大のボトルネックとなる場所になります。そしてデータは10億ピクセル/秒(大体8 x フルHD1080p60fpsと同じ)の画像処理プロセッサを通ってチップに戻ります。チップのこの部分はカメラセンサーからの生のRGBデータを使用可能なデータに変換し、さらに色彩を強調してノイズを取り除きます。
最後にチップの中でも最も面白い部分である、ニューラルネットワークプロセッサ、またはNPUです。処理はデータがSRAMアレイに記録されるところから始まります。ここでコンピューターの仕組みに詳しい人を含む大勢の方が、「SRAMとは一体全体何なんだ?」と思っているかもしれません。 一番比較しやすいのが、あなたのコンピューターのプロセッサ内にある、共有L3キャッシュです。さて、これがどういう意味かと言いますと、非常に速いが、高価なストレージであるという事です。現在、インテルの一番大きなL3キャッシュは45MB(2010年まで16MB、2014年までは24MB)です。ほとんどの一般消費者向けデスクトップ/ノートパソコンのプロセッサは8~12MBのL3キャッシュを採用しています。テスラのニューラルネットワークプロセッサは驚異の64MB SRAMを使っており、これは2つのニューラルネットワークプロセッサをサポートするために2つの32MB SRAMセグメントに分割されています。テスラはこの大きなSRAM容量が、市場に存在する他のどんなチップよりも彼らに優位性をもたらせたと考えています。
これはすべてのカメラとセンサーのインプットを足したフレーム1つを保存、レンダリング、処理するのには十分なメモリかもしれません。しかしここで使われるフレームは質の悪いJPEGではなく、ロスレスの大きなものなので、恐らく十分ではないでしょう。もしカメラが本当に60fpsで作動するならば、SRAM内のフレーム1つあたりカメラ全部の分を合わせて、3.84ギガバイト/秒のデータ処理スピードになります。1つのフレームはさらに大きい物になると考えられます。ここで、当て推量で秒あたり何ギガバイトになるという数値は出したくないのですが、68ギガバイト以下になるのは確かです。
すべてのデータは‘チップ上のネットワーク=Network On a Chip’、もしくは‘NoC’と呼ばれる幹線道路(青い部分)を通り、次にバンド幅が68ギガバイト/秒になるLPDDR4 DRAMを通ります。テスラはAutonomy Dayでのプレゼンテーションで、これで十分だという認識を示していましたが、さらに良いものにできる筈です。次世代製品ではテスラが改善を加えてくると予測されます。今現在、ボトルネックがDRAMの処理能力なのか、それともSRAMの容量なのかは明確ではありません。
ニューラルネットワークプロセッサ(NPU)は驚異的にパワフルなツールです。NPUは多くのデータを扱えますが、コンピューター上のタスクには、NPU用に調整されていないか、そもそもNPUに向いていないタスクもあります。。 そこでGPUの登場です。このチップに搭載されるGPUは、テスラ用には控え目なパフォーマンスのもので、1Ghzで動き、600GFLOPSの性能です。テスラによりますとGPUはデータ処理後のプロセスを担っていて、人間が理解できる写真や動画の作成もここに含まれる可能性があります。しかし、プレゼンテーションでGPUの役割についてテスラが説明した感じを見ると、次のバージョンのチップには今よりもかなり小さいGPUが搭載されると予想されます。
さらに他にも、一般的な処理タスクで、CPUのほうがニューラルプロセッサより得意なものもあります。テスラの説明によりますと、2.2Ghzで動くチップには12のARM Cortex-A72 64ビットCPUが搭載されています。もう少し正確な言い方をすると、3つの4コアCPUが入っています。しかし、テスラがARM Cortex-A72 アーキテクチャを選択したのには少し困惑させられます。Cortex-A72は2015年のアーキテクチャです。それ以降、A73、A75、そして今年5月にはA77アーキテクチャもリリースされました。イーロン・マスク氏とチームは2年前にチップのデザインを始めた際に手に入ったのがこれだったから、と説明しました。マルチスレッドパフォーマンスを重要視していた、つまり、1つや2つのより新しいかパワフルなプロセッサよりも、3つの古いプロセッサを使用する事を優先したならば、恐らく価格を抑ることができるので、合点がいきます。マルチスレッドには通常、タスクを均等に配分するために、プログラミングにより多くの労力を割かなければならないのですが、そこはテスラです。この会社にとっては朝飯前でしょう。何はともあれ、このチップのCPUパフォーマンスは以前のHW2バージョンに比べて2.5倍高いものとなっています。
NVIDIAは面子を保つのに躍起
ここまでかなりテクニカルな話をしてきましたので、ちょっと休憩をしましょう。面白い話があるのです。テスラのAutonomy Dayの後、NVIDIAはブログを更新し、テスラが‘自動運転のハードルを上げた’事に関して賛辞を送りました。その直後、NVIDIAは意味のない比較計算をしながら自画自賛し、自らの面子を保とうとしたのです。
テスラのHW2はNVIDIA Xavier チップを使っており、性能は21~30TOPS(terra operation per second)でした。テスラの新しいHW3チップは144TOPSの処理能力になります。
テスラのプレゼンテーションではNVIDIA Xavierチップは21TOPSと言及されていました。NVIDIAはブログの中で実際には21ではなく30TOPSであると訂正しようとしていました。NVIDIAのXavierチップは多目的用に作られていて、様々なクライアントのニーズにできるだけ合わせられるようになっています。それ故、チップにはニューラルネットワークプロセッサが無いのですが、ソフトウェアとディープラーニングに特化したハードウェアを使う事によりシミュレーションする事ができるのです。テスラが21 TOPSと言ったのは、チップ上のGPUでニューラルネットワークをシミュレーションした結果です。テスラの採点基準は非常にシンプルです。
「テスラのソフトウェアは、このハードウェア上で何TOPSになるか?」 です。これは、このハードウェアがチップをフル活用するためのソフトウェアと合わさった時にTOPS値がどうなるのか、そしてソフトウェアの最大TOPS値はいくつになるのか、とはまったく違う話です。理論的には、チップが別のシナリオで何か別のタスクを行うために使われたとしたら、30TOPSという数字が出るかもしれませんが、そんな計算には何の意味もないのです。こうは言いましたが、NVIDIAが他の(未来の)クライアントのために数字を訂正したのは理にかなっています。
ここで覚えておきたいのは、複雑なソフトウェアのベンチマークをする際、その基準は特定のソフトウェアがどれだけそのパフォーマンスを発揮できるかが全てだという事です。従って理論的に一番優れているハードウェアが必ずしもベストなものにはならないという事なのです。
過去、私達には数値演算コプロセッサを使用した汎用プロセッサの選択肢しかありませんでした。それからグラフィックス・コプロセッサが登場し、現在ニューラルネット・コプロセッサが出てきました。しかし皮肉な事に、このケースでは、CPUはニューラル処理ユニットではなくコプロセッサに近いものになります。基本的にテスラがやった事は、究極に限定されたタスクを処理する事に特化し、それにかけては相当優れたプロセッサの開発なのですが、汎用処理に関しては性能の良くないものになってしまったのです。という訳で、このチップが上手い事やれる仕事は私達が住むこのマトリックス世界の路上を走る事だけなのですが…そのレベルは相当高いです。

NVIDIA DRIVE AGX Pegasus
NVIDIAはプライドを守るために、さらに他の事も言い出しました。XAVIERを自社のDRIVE AGX Pegasus製品内のパワフルなGPUと組み合わせると、160TOPSの処理能力になると言うのです。しかしテスラの目的に使用された時に、ニューラルネットワークプロセッサをシミュレーションしなければならないため、その70%しか使えないと仮定すると最大112TOPSとなり、多くの無駄が生じる事になります。NVIDIAはDRIVE AGX Pegasusは2つのユニットを平行に積む事によって320TOPS出せるとも言っていますが、テスラ用には現実的ではないでしょう。
インターネットのスピードについて考えた時、一般的に回線速度だけではなく、レイテンシ(遅延時間)、応答速度も気にされるかと思います。テスラも隣同士に配置されているDRAMからチップに到達する情報のレイテンシについて不満を述べています。脆弱なNVlinkケーブルを使って相互接続された複数のチップから移動するデータのレイテンシは受け入れられるレベルには無いでしょう。
さらに、電気自動車が原子炉ではなくバッテリーで動いているという条件も考慮されていません。この4つのチップを使った解決策を実行した場合、高速道路に到達する前にバッテリーが無くなるでしょう。ここでは効率が鍵なのです。
NVIDIAの解決策はパフォーマンス用チップを組み合わせる事にフォーカスしています。複数のコア、より良いCPUにGPU、そしてケースバイケースで一から作るのではなくNVlinkを使っての接続、というマーケティング上の必要性に固執しています。完璧なソフトウェアを作ろうとする企業や、何らかのプロジェクトに携わっている大学用には素晴らしいと思いますが、現実世界で活用しようとした際には効率が悪いのです。
Hardware ver.4
さて、ここまでがテスラのハードウェアver.3でした。ではver.4はどういうものになるのでしょうか?現在分かっているのは、さらなる安全性を目指しているという事です。 これによって分かるのは、古い車に新しい機能を教え込む事にはフォーカスしない、という事なのですが、完全にそれをしないという訳でもない、という事です。ここに私が予想するver.4のハードウェアの変更点と改善点を、可能性の高いものから挙げていきます。
• テスラがアーキテクチャをデザインし始めた時期を考えると、次に新し目のCPUを使う可能性は高く、Cortex A75になるのではないかと思われます。処理能力の向上により、電力をセーブしてより多くのスペースをチップ上に確保し、より重要な他のコンポーネントに余力を残す事ができます。
• テスラはLPDDR5にアップグレードするかもしれません。その場合目覚ましくスピードが速くなり、電力消費も少なくなります。しかし、HW4のデザインプロセスが既に始まっている、もしくはコストを抑えるために、LPDDR4Xを使うかもしれません。より低い電圧を使う事により、LPDDR4Xは電力をセーブする事ができ、それでも複数のチップを平行に並べる事によってスピードを上げられます。ただしこの配置ではHW3に比べて電力の節約量は少なくなります。しかしいずれにせよ、トータルではHW3よりも性能の良いものになるでしょう。
• より多くのSRAMを使い、さらに改善されたニューラル処理ユニット
• チップが処理できるかにかかってきますが、テスラのHW4はより高い解像度と、もしかしたら高いフレームレートを備えた新しいカメラとセンサーを搭載させるかもしれません。コンピューターが対象物の詳細を、より遠くから、より正確に認識するのに、より解像度の高い画像は重要になってきます。
• アップグレードされた画像処理プロセッサ(ISP)もあり得るかもしれません。 テスラはチップをできるだけ安く、パワフルなものにしたがっていました。そのためHW3ではチップのインプットの処理能力と、ISPの処理能力に大きな隔たりがあり、目的によって(電力を抑えたい、省スペース化したい、コストを抑えたい)よりしっかりした、もしくは2つ目のISPが必要となります。
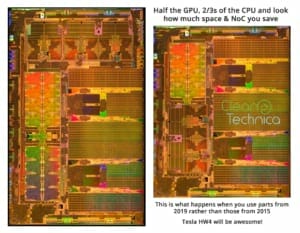
• より小さいGPUもあり得ます。HW3のSoCにそこそこの大きさのGPUがあるのは、ニューラルネットワークに全ての処理タスクが移されていないからです。この大きさのGPUを残す事によって、テスラはプログラマーに残りのGPUの処理タスクをNPUかCPUに移植する十分な時間を与えようとしているのかもしれません。GPUを完全に取り去るのは不可能かもしれませんが、GPUを小さくしてSoCが小さくなるとNoCも小さくすることができ、SRAMの増量など、より重要なコンポーネントに予算も場所も割くことが出来ます。
おわりに
テスラのHW3コンピューターはとんでもない化け物です。7倍のフレームを取り扱い、7倍の大きさのニューラルネットを持ち、プレゼンテーションで言われたように、「その使用方法は多くある」のです。コンピューターオタクとしては、Autonomy Dayプレゼンテーションはディズニーランドに行くよりも楽しいものでした。完全自動運転を目指すための第一歩は、優先順位を明確にする事であり、テスラは確実にそれをやっています。
一般に十分に知れ渡っていないポイントがいくつかあり、そのせいでテスラが完全自動運転開発においてかなり優位に立っているにも関わらず、過小評価されたり、十分に理解されずにいる側面もあります。もう一つよく似た問題例をご紹介します。電気自動車を生産開始したすべての他のメーカーは、かなり進んだ技術を有していますが、テスラの2012年モデルSに勝るものが未だに出てきていません。そしてこれは電気自動車の観点からであって、コンピューター、ソフトウェア、UIの側面を無視しての話です。競合他社の技術が追い付かない理由は簡単で、垂直統合がなっていないのです。
もう少し簡単にご説明しましょう;あなたのメーカーがウェブサイトを作ろうとしていると仮定します。ブログパーツやページをドラッグ&ドロップし、テキストを打ち込めば出来上がるフォーマットを提供しているプラットフォームに行くか、もしくはプロフェッショナルなサイトを作るために一から専任のプログラマーから成るチームを立ち上げるという選択肢があります。既存の自動車メーカーは電気自動車と自動運転に関して前者を選ぼうとしているのです。別々の会社からレゴブロックを注文し、上手く組み合わされる事を願っています。上手くいかない場合はナイフを使ってパーツの一つを削り取り調整します。一方テスラは、イーロン・マスク氏にいいねボタンを押されたこのツイートのようなものなのです。
テスラの新しいHW3コンピューターに関しては、全てがぴったりとフィットするようにできています。マスク氏は、完全自動運転は電気自動車と組み合わせないと意味が無いと言っており、彼は正しいのです。さらに正確に言いますと、内燃機関エンジンを積んだ車でそれをやる価値は無いという事です。トルクが即座に反応しないと、車の衝突や滑りやすい道路コンディションを考えた時に、自動運転はより非効率になり安全面でも劣ってしまいます。これに関しては別の記事でお話ししましょう。
しかし一番重要な理由は、ガソリン車のようなもうすぐ絶滅する死にかけの商品に投資するのは馬鹿らしいという事です。シンプルな話です。
電気自動車用の自動運転システムを作るときに、どうしても電力効率よりも安全性が重要視されてしまいますが、他自動車メーカーやチップメーカーからは最低十分の考慮もされていないようです。これもテスラが何光年も先に行っている理由の一つになるのです。
(翻訳・文 杉田 明子)







コメント
コメント一覧 (4件)
テスラが汎用チップと専用チップを比較して、(特定の条件下に限ることを条件に)うちのほうが優れているといったことに対して
「テスラのチップのほうが優れている」という部分だけが取り沙汰される記事も散見されたので、それに対してnvidiaが対応しただけでは?
また、記事のおわりにで言われていることはAndroid端末とiPhoneのような関係です。
ある時点の物事を早く実現したいとき、専用品を用意するほうが有利です。
しかしながらいずれは汎用品で十分になり、最適化も進んでいきます。その後は汎用品が優位に立ちます(長くなるので理由は割愛させていただく)。
専用品を用意してなお、自動運転車としての完成度で他社の後塵を拝するテスラは、どちらかというとかなり遅れていると言えるでしょう。
「このチップが上手い事やれる仕事は私達が住むこのマトリックス世界の路上を走る事だけなのですが…そのレベルは相当高いです。」等々の文章は非常にシンプルで疑問の余地は無いと思います。英文を自分で読める人間になら特に問題はありませんがこの様な翻訳記事については日本語化する意義は十分あると思います。
同時にテスラ社の要素技術(革新的な)をデータで読み解け(数字的な)、自動運転車の統合化に置けるSoCの重要性に気づけるという意味では素晴らしい記事だと思います。あまりTeslaの関連にSpaceXやNeuralinkの話を出すのは的確ではありませんが、Teslaに置いても同様に要素要素の性能諸元を真っ当な技術で開拓する姿勢は「進んでいる」と評価できると思います。
特定の用途に専用設計された都合のいい数字だけを比較しても意味がない
テスラは自動運転で遅れを取っているのは明白で、テスラの完全自動運転など毎度の詐欺口上であることを理解すべきだ
アドバイスをするならば
バカはイメージで記事を書く前に、調査をするべきだ
翻訳する人間も価値がない文章を翻訳してゴミを増やす前に、翻訳すべきかどうか考えたほうが良いだろう
賢者 様、コメントありがとうございます。
そうですね、自動運転の進捗の定義にはいろいろなものがあり、当サイトではコンセプトカーやコンプライアンスカー(法的要件を満たすために少量生産している車両)についてはあまり扱わないこととしています。それらは企業の「広告宣伝・広報」の一部であって、ビジネスではないと考えています。
例えばWaymoはすでに米国の複数の州で無人のレベル4自動運転を実現しています。これは素晴らしいことですが、この車両は量産用を目指しているわけではなく、コンピュータの世界でいえばスーパーコンピューターの開発のようなもの。すなわち、数年というレベルで一般の方々の手に降りてくるようなコストの商品ではありません。Waymoの自動運転システムはハードウェアコストだけで1500万円程度と言われ(ソフトウェアの開発減価償却は含まれません)、仮に楽観的にグロスマージン20%と仮定すると販売価格は、車両が100万円としても8000万円になってしまいます。
そういう意味で、市販車両に実際にすでに搭載されている(今月日本で納車開始されると言われるモデル3には、このHW3が全車搭載されています)ハードウェアについてのデータですので、もう数週間で一般の消費者の方々は、最初はエミュレーションモードだったとしても恩恵を受け始めるわけで、内容としては意味のあるものだと考えています。少なくとも、商用で実際に入手可能な自動運転ハードウェアの中では、テスラ・日産・アウディ・BMWがそれぞれ出してきていますが、逆にそれ以外のメーカーは商品すらまだ準備できていないわけですから、先を行っていると判断することも可能かと思います。
>テスラは自動運転で遅れを取っているのは明白
当サイトは、データや事実に基づいて議論することをポリシーとしており、それに反する書き込みに関しては、他の読者の方の役に立たないものは掲載をしない方針です。大変恐縮ですが、上記について、データなどに基づくご説明をもう少しいただければと思います。
https://blog.evsmart.net/tesla-model-x/autopilot-2019-32/
ご参考:こちらはHW2の古いモデルですが、リリース後1週間も経っていない最新ソフトウェアで自動運転レベル2がこんな感じで走行できる、という記事を昨日リリースしました。よろしければご覧ください。